



Index
Einleitung
Konfigurations-Optionen
Initiale Zeitplanung
Inter-check delay
Dienst-Auslassung
Maximum der gleichzeitigen Dienst-Überprüfungen
Zeiteinschränkungen
Normale Zeitplanung
Zeitplanung bei Problemen
Host-Überprüfungen
Verzögerungen im Zeitplan
Planungs-Beispiel
Optionen aus der Dienst-Definition die die Zeitplanung beeinflussen
Viele User fragen, wie die Dienst-Überprüfungen in verschiedenen Situationen von Nagios geplant werden, bzw. wie sich diese Zeitplanung von der Ausführung und der Ergebnisverarbeitung unterscheidet. Dieses Kapitel der Dokumentation soll hierauf näher eingehen...
Bevor wir beginnen, müssen einige Konfigurations-Optionen beachtet werden, die beeinflussen, wie Dienst-Überprüfungen geplant, ausgeführt und verarbeitet werden. Jede Dienst-Definition enthält drei Optionen, die angeben wann und wie eine Dienst-Überprüfung von Nagios geplant und ausgeführt wird. Diese drei Optionen sind:
Ferner gibt es vier Konfigurations-Optionen in der Haupt-Konfigurationsdatei, die Dienst-Überprüfungen beeinflussen. Dies sind:
Wir werden später noch genauer betrachten, wie genau diese Optionen die Planung von Dienst-Überprüfungen beeinflussen. Zuerst betrachten wir aber, wie Überprüfungen initial beim Programmstart (oder Re-Start) von Nagios geplant werden.
Wenn Nagios gestartet oder neu gestartet wird, versucht es die anstehenden Dienst-Überprüfungen so zu planen, das es die Load auf dem lokalen, aber auch auf dem entfernten Host minimiert. Dies wird getan, indem Nagios die initialen Überprüfungen zeitlich verteilt und einige auslässt. Mit der zeitlichen Verteilung (auch "inter-check delay" genannt) wird die Last auf dem lokalen Host (auf dem Nagios läuft) minimiert bzw. gleichmässig verteilt. Die Auslassung sorgt für eine Last-Minimierung bzw. -Ausgleichung auf den entfernten (den zu überwachenden) Hosts. Beide Funktionen werden später in diesem Kapitel diskutiert.
Auch wenn Nagios versucht die initialen Überprüfungen gleichmässig und lastverteilend zu planen, kann es Anfangs etwas "zufällig" und "chaotisch" vorkommen. Dies liegt daran, dass nicht alle Überprüfungen in dem gleichen Intervall vorgenommen werden, einige etwas länger brauchen als andere und natürlich auftretende Host- oder Dienst-Probleme die Planung von einer oder mehreren folgenden Überprüfungen ändern können. Jedenfalls versuchen wir hiermit einen ausgeglichenen Start zu erreichen und glücklicherweise erreicht die initiale Zeitplanung mit der Zeit eine recht gut Last-Balance.
Hinweis:
Wird Nagios mit dem -s-Schalter gestartet, zeigt es Informationen zur initialen Zeitplanung
der Dienst-Überprüfungen, wie z.B. den "inter-check delay", "interleave factor", die erste und letzte
Dienst-Überprüfung, etc. Ausserdem legt Nagios ein neues Status Log an, das darüber Auskunft gibt,
wann genau welche Überprüfung eingeplant wurde. Da dieser Schalter allerdings das Status Log überschreibt,
sollte der Schalter nicht genutzt werden, wenn eine andere Instanz von Nagios läuft.
Nagios nimmt den Betrieb nicht auf, wenn es mit dem Schalter gestartet wird.
Wie bereits zuvor erwähnt versucht Nagios die Last gleichmässig zu verteilen, indem die Überprüfungen zeitlich gleichmässig verteilt werden. Diese zeitliche Verteilung aufeinander folgender Überprüfungen wird "inter-check delay" genannt. Die Berechnung dieses delay-Wertes kann durch die Änderung der inter_check_delay_method-Variable in der Haupt- Konfigurationsdatei beeinflusst werden. Da diese Variable im normalen Betrieb auf "smart" gesetzt ist, werden wir näher erläutern, wie diese "smart" Berechnung genau funktioniert.
Wenn die inter_check_delay_method-Variable auf "smart" gesetzt ist errechnet Nagios den "inter-check delay"-Wert auf der folgenden Art und Weise:
inter-check delay = (Summe der Intervalle aller Dienstüberprüfung) / (Gesamtanzahl der Dienste)2
Ein Beispiel:
Nehmen wir an, es wurden 1.000 Dienste konfiguriert, die alle ein Überprüfungs-Intervall von 5 Minuten
haben. Die Summe aller Intervalle liegt somit bei 5.000 (1.000 * 5). Das heisst, dass das durchschnittliche
Überprüfungs-Intervall jedes Dienstes bei 5 Minuten liegt (5.000 / 1.000). Durch diese Information wissen
wir, dass wir (durchschnittlich) alle 5 Minuten 1.000 Dienst-Überprüfungen einplanen müssen. Das wiederum
ergibt einen Wert für den inter-check Delay von 0.005 Minuten (0.3 Sekunden), mit denen die Dienst-Überprüfungen
zeitlich verteilt geplant werden. Bei einer Verteilung von 0.3 Sekunden können wir somit garantieren,
dass Nagios jede Sekunde 3 Dienst-Überprüfungen einplant und/oder ausführt. Durch diese zeitliche Verteilung
erreichen wir eine Last-Optimierung auf dem lokalen Server, auf dem Nagios ausgeführt wird.
Wir bereits beschrieben hilft der inter-check Delay die Last auf dem lokalen Nagios-Host gleichmässig zu
verteilen. Was ist aber mit den zu überwachenden Host? Ist es nötig hier auch eine gleichmässige Verteilung
der Last nötig? Und wenn ja warum?
Ja, es ist wichtig und ja, Nagios nimmt sich diesem Problem an. Die gleichmässige Lastverteilung auf
remote Hosts ist gerade mit der Einführung von paralleler Dienst-Überprüfung
wichtig geworden. Nehmen wir an auf einem Host wird eine grosse Anzahl von Dienst überwachtund die Überprüfungen
würden nicht verteilt; der Host könnte annehmen, er wäre das Opfer einer SYN-Attacke, besonders wenn diese
Dienste auch über den gleichen Port überprüft werden. Ausserdem ist die Lastverteilung auf den zu überwachenden
Hosts ein sehr nettes Thema...
Die Berechnung des "Auslassungs-Faktor" kann dadurch beeinflusst werden, das der der service_interleave_factor-Variable in der Haupt-Konfigurationsdatei ein Wert gegeben wird. Da dieser Wer im normalen meistens auf "smart" gesetzt wird, werden wir hier erklären, wie Nagios diese Berechnung vornimmt. Es kann auch ein eigener Auslassungs-Faktor gesetzt werden, anstatt sich diesen Wert durch Nagios berechnen zu lassen. Wird der Wert auf "1" gesetzt, wird dieses Feature deaktiviert.
Wenn die service_interleave_factor-Variable auf "smart" gesetzt wird, errechnet Nagios den "Auslassungs-Faktor" (interleave factor) auf der folgenden Art und Weise:
interleave factor = aufrunden ( Gesamtanzahl der Dienste / Gesamtanzahl der Hosts )
Ein kleines Beispiel:
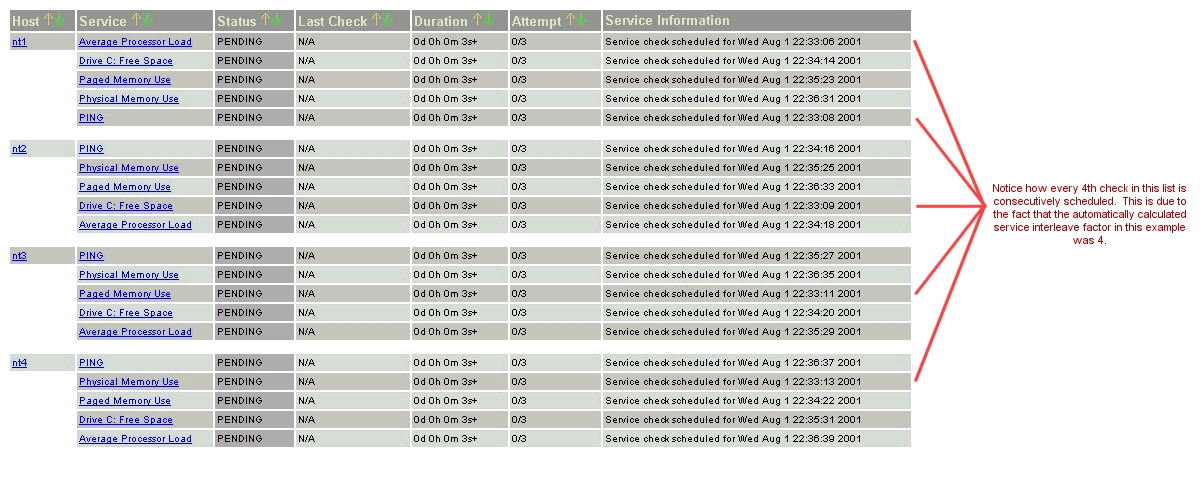
Angenommen es sind 1.000 Dienste und 150 Hosts zur Überwachung definiert. Nagios würde hier einen Auslassungs-Faktor
von 7 berechnen. D.h. bei der initialen Zeitplanung plant Nagios den ersten Dienst, lässt die nächsten sechs Dienste
aus und plant dann wieder den siebten, usw. usw. Dieser Prozess wird von Nagios so lange fortgesetzt, bis alle Dienste
zur Überprüfung eingeplant sind. Da die Dienste erst nach dem Namen des dazugehörigen Hosts sortiert und anschliessend
geplant werden, hilft dieser Mechanismus die Last auf dem zu überwachenden Host zu minimalisieren.
Das folgende Bild beschreibt wie Dienst-Überprüfungen geplant werden, wenn das "interleave"-Feature deaktiviert wurde (service_interleave_factor=1) und wenn die service_interleave_factor-Variable auf 4 gesetzt wird.
| Überprüfungen ohne "Auslassung": | Überprüfungen mit "Auslassung": |
|
|
|
|
|
|
|
|
Maximum der gleichzeitigen Dienst-Überprüfungen
Um zu verhindern das Nagios alle CPU-Ressourcen verschlingt, kann die maximale Anzahl der gleichzeitigen Dienst-Überprüfungen mit der max_concurrent_checks-Option in der Haupt-Konfigurationdatei vorgegeben werden.
Der Vorteil dieser Einstellung ist, dass die CPU-Nutzung von Nagios reguliert werden kann. Der Nachteil liegt darin, dass Nagios mit den Dienst-Überprüfungen nicht mehr hinterherkommt, wenn dieser Wert zu gering gesetzt wird. Wenn es Zeit wird eine Dienst-Überprüfung auszuführen, stellt Nagios sicher, dass nicht mehr als x Dienst-Überprüfungen gerade ausgeführt werden oder auf die Verarbeitung ihrer Ergebnisse warten (x gibt den Wert der max_concurrent_checks-Option an). Ist dieses Limit erreicht, stellt Nagios die Ausführung der Überprüfung solange zurück, bis eine vorherige Überprüfung abgeschlossen wurde. Wie errechnet man aber einen sinnvollen Wert für die max_concurrent_checks-Option?
Hierfür sollten einige Dinge bekannt sein:
Als nächstes kann mit der folgenden Formel ein vernünftiger Wert für die maximale Anzahl der gleichzeitigen Überprüfung errechnet werden...
max. Anzahl gleichzeitiger Überprüfungen = aufrunden( max ( Service-Reaper-Frequenz , durchschnittliche Zeit zur Überprüfungs-Ausführung ) / inter-check Delay )
Der errechnete Wert sollte ein vernünftiger Beginn zum Ausprobieren der max_concurrent_checks-Variable darstellen. Dieser Wert kann ein bisschen erhöht werden, wenn Dienst-Überprüfungen "hinten über fallen", bzw. verringert werden, wenn Nagios zu viel CPU-Zeit verbraucht.
Nehmen wir an es werden 875 Dienst überwacht, jeder mit einem durchschnittlichem Überprüfungs-Intervall von 2 Minuten. Das heisst, das der inter-check Delay bei 0,137 Sekunden liegt. Wenn die Frequenz des Service-Reapers bei 10 Sekunden liegt, kann der Wert für die max. Anzahl von gleichzeitigen Überprüfungen wie folgt berechnet werden (wir nehmen dabei an, dass die durchschnittliche Laufzeit einer Überprüfung unter 10 Sekunden liegt):
max. Anzahl gleichzeitiger Überprüfungen = aufrunden( 10 / 0.137 )
In diesem Fall liegt der errechnete Wert bei 73. Das macht Sinn, da Nagios (im Durchschnitt) jede Sekunde 7 neue Überprüfungen einplant und nur alle 10 Sekunden die Ergebnisse verarbeitet. Das heisst das zu gegebenem Zeitpunkt etwas über 70 Dienst-Überprüfungen entweder gerade laufen oder auf die Verarbeitung ihrer Ergebnisse warten. In diesem Fall, würden wir empfehlen den Wert für die max. Anzahl von gleichzeitigen Dienst-Überprüfungen auf ca. 80 zu erhöhen, da es immer zu leichten Verzögerungen bei der Verarbeitung der Überprüfungs-Ergebnisse kommen kann. Um diesen Wert per Hand abzustimmen muss aber sicher ein bisschen ausprobiert und getestet werden, bis der optimale Wert gefunden ist.
Die check_period-Option gibt den Zeitraum an, indem Nagios Dienste überprüfen darf. Befindet sich der Zeitpunkt zu dem eine Überprüfung ausgeführt werden soll nicht in einem angegebenen gültigen Zeitrum, wird Nagios die Überprüfung nicht ausführen ,egal in welchem Status sich der jeweilige Dienst befindet. Stattdessen wird Nagios die Dienst-Überprüfung zum nächst gültigen Zeitpunkt neu einplanen. Befindet sich der Überprüfungs- Zeitpunkt in einem gültigen Zeitraum, wird die Überprüfung ausgeführt.
Hinweis:
Auch wenn ein Dienst zu einem gegebenen Zeitpunkt nicht ausgeführt werden darf, wird Nagios erstmal trotzdem planen
die Überprüfung zu diesem Zeitpunkt auszuführen. Dies kommt vor allem bei der initialen Zeitplanung vor. Dies heisst aber
nicht, dass Nagios die Überprüfung zu diesem Zeitpunkt auch ausführen wird! Wenn es an der Zeit ist die Überprüfung
auszuführen, wird Nagios überprüfen, ob die Überprüfung zu diesem Zeitpunkt erlaubt ist, oder nicht. Wenn nicht,
wird Nagios die Überprüfung nicht ausführen und wird die Überprüfung dafür zu einem späteren Zeitpunkt neu einplanen.
Also nicht verwirren lassen, die Planung und die Ausführung von Dienst-Überprüfung sind zwei absolut verschiedene
(wenn auch miteinander verknüpfte) Dinge.
In einer idealen Welt würde es keine Netzwerkprobleme geben. In diesem Fall bräuchte aber auch niemand ein Monitoring-Tool. Wenn also alles gut läuft und sich ein Dienst in einem "OK"-Status befindet, nennen wir das "normal". Dienst-Überprüfungen werden in diesem Fall durch den angegebenen Wert in der check_interval-Option angegeben. Das wars...einfach, oder?!?
Was passiert aber, wenn ein Problem mit einem Dienst auftritt? In diesem Fall ändert sich die Planung dieser Dienst-Überprüfung. Falls die max_attempts-Option in der Dienst-Definition mit grösser als 1 konfiguriert wurde, wird Nagios den Dienst nochmals überprüfen, bevor eine Entscheidung fällt, das hier ein Problem herrscht. Während der Dienst erneut geprüft wird (bis zu max_attempts Male), befindet sich der Dienst ein einem "soften" Status (wie hier beschrieben) und die Dienst-Überprüfung wird mit der Frequenz neu eingeplant, wie in der retry_interval-Option angegeben.
Hat Nagios den Dienst so oft erneut überprüft, wie mit der max_attempts-Option angegeben und der Dienst befindet sich immernoch in einem "nicht-OK"-Status wechselt Nagios den Status für diesen Dienst in einem "harten" Status, sendet eine Benachrichtigung (falls anwendbar) und plant die weiteren Überprüfungen dieses Dienstes mit der in der check_interval-Option angegebenen Frequenz.
Natürlich gibt es auch hier (wie eigentlich überall und immer) Ausnahmen. Wenn eine Dienst-Überprüfung in einem "nicht-OK"-Status resultiert, überprüft Nagios den Host der mit dem Dienst verknüpft ist um zu sehen, ob der Host up ist oder nicht (bitte den Abschnitt weiter unten für weitere Informationen hierfür beachten). Ist der Host nicht up (also down oder nicht erreichbar), wird Nagios den Dienst sofort in einen "harten" nicht-OK-Status setzen und die Anzahl der Überprüfungs-Versuche auf 1 setzen. Da sich der Dienst nun in einem "harten" nicht-OK-Status befindet wird die erneute Überprüfung nun durch die check_interval-Option und nicht durch die retry_interval-Option bestimmt.
Anders als Dienst-Überprüfungen werden Host-Überprüfungen nicht auf einer regulären Basis geplant. Stattdessen werden sie bei Bedarf ausgeführt, wenn Nagios eine Notwendigkeit sieht. Diest ist eine oft gestellt Frage, daher sollte dies hier klargestellt werden.
Ein Umstand bei dem Nagios den Status von Hosts überprüft ist, wenn eine Dienst-Überprüfung in einem nicht-OK-Status endete. Nagios überprüft dann den Host um zu erkennen, ob dieser up, down oder nicht erreichbar ist. Falls die erste Host-Überprüfung einen nicht-OK-Status hervorbringt, wird Nagios den Host weiter überprüfen, bis entweder (a) die maximale Anzahl von Host-Überprüfungen (durch die max_attempts-Option der Host-Definition angeben) erreicht wurde oder (b) eine Host-Überprüfung in einem OK-Status endet.
Hinweis:
Wenn Nagios den Status eines Hosts überprüft, hält es alle andere Tätigkeiten an (Ausführung von neuen Dienst-
Überprüfungen, die Verarbeitung von Ergebnissen, etc.). Dies kann natürlich alles ein bisschen verlangsamen und
wartende Dienst-Überprüfungen verursachen. Es ist aber für Nagios nötig den Status des Hosts zu erkennen, bevor
es fortfährt und Aktionen für den/die Dienst(e) auslöst, die ein Problem haben.
Es sollte beachtet werden, dass die Planung und Ausführung der Dienst-Überprüfung mit grösster Mühe erfolgt. Individuelle Dienst-Überprüfungen sind daher Ereignisse mit einer geringeren Priorität in Nagios. Daher kann es hier zu Verzögerungen kommen, wenn ein Ereigniss mit einer höheren Priorität ausgeführt werden muss. Solche Ereignisse mit einer hohen Priorität sind z.B. Rotation von Logfiles, externe Befehls-Überprüfungen und die Verarbeitung von Ergebnissen. Ausserdem können Host-Überprüfungen die Ausführung und Verarbeitung von Dienst-Überprüfungen verlangsamen.
Die Planung von Dienst-Überprüfungen, deren Ausführung und die Verarbeitung derer Ergebnisse ist ein bisschen schwer zu verstehen, deshalb versuchen wir es einfach zu halten. Schauen wir uns das folgende Diagramm an, es wird im folgenden Abschnitt erklärt.
| Abbildung 5. |

|
Als erstes, die Xn-Ereignisse sind "Reaper-Events", die mit einer durch die in der Haupt-Konfigurationsdatei befindlichen service_reaper_frequency-Option angegebenen Frequenz geplant werden. "Reaper-Events" sammeln die Ergebnisse der Dienst-Überprüfungen ein und verarbeiten diese. Sie bilden die Kern-Logik von Nagios, stossen Host-Überprüfungen, "Event-Handler" und wenn nötig Benachrichtigungen an.
In dem Beispiel hier, wurde eine Dienst-Überprüfung für den Zeitpunkt A eingeplant. Nagios hinkt in seiner Queue allerdings hinterher und kann die Überprüfung erst zum Zeitpunkt B ausführen. Die Überprüfung des Dienstes endet zum Zeitpunkt C, die Zeit-Differenz zwischen C und B ist also die wirkliche Laufzeit der Überprüfung.
Das Ergebnis der Dienst-Überprüfung wird aber nicht sofort nach Beendigung der Überprüfung verarbeitet. Die Ergebnisse werden gespeichert um später bei einem "Reaper-Event" verarbeitet zu werden. Der nächste "Reaper-Event" tritt zum Zeitpunkt D auf, deshalb ist dies der Zeitpunkt zu dem die Ergebnisse verarbeitet werden (der wahre Zeitpunkt kann auch etwas später als D sein, da mit dem gleichen "Reaper-Event" evtl. auch andere Ergebnisse mitverarbeitet werden müssen).
Zu dem Zeitpunkt an dem der Reaper-Event die Ergebnisse der Dienst-Überprüfung verarbeitet, plant dieser auch die nächste Überprüfung des jeweiligen Dienstes und platziert diese in der Ereignis-Queue von Nagios. Wir nehmen an, dass die Überprüfung in einem OK-Status endete, die nächste Überprüfung wird also für den Zeitpunkt E angesetzt, genau nach einer Zeitspanne, die durch die check_interval-Option angegeben wurde. Man beachte, dass die nächste Überprüfung nicht nach dem wahren Zeitpunkt der Ausführung berechnet wird! Allerdings gibt es dafür eine Ausnahme (gibt es die nicht immer?), nämlich wenn sich der Zeitpunkt der wirklichen Ausführung (Zeitpunkt B) nach dem Zeitpunkt der eigentlich nächsten Ausführung (Zeitpunkt E) befindet. Nagios kompensiert dieses allerdings durch eine Angleichung des nächsten Ausführungszeitpunktes. Dies ist nötig, damit Nagios irgendwann nicht "durchdreht" indem es versucht Zeitpunkt in der Vergangenheit zu planen...
Optionen aus der Dienst-Definition die die Zeitplanung beeinflussen
Jede Dienst-Definition enthält eine normal_check_interval- und eine retry_check_interval-Option. Hoffentlich kann dieser Abschnitt erklären, was diese beiden Optionen bewirken, wie sie sich auf die max_check_attempts-Option aus der Dienst-Definition beziehen und wie diese die Zeitplanung der Dienst-Überprüfungen beeinflussen.
Vorab, die normal_check_interval-Option ist das Interval mit dem ein Dienst unter "normalen" Bedingungen überprüft wird. "Normale" Umstände bedeuten, dass sich der Dienst in einem OK-Status oder einem "harten" nicht-OK-Status befindet.
Wenn ein Dienst das erste Mal von einem OK- in einen nicht-OK-Status wechselt, gibt es bei Nagios die Möglichkeit vorübergehend die Ausführung von hieraus folgenden Überprüfungen des Dienstes zu beschleunigen oder zu verlangsamen. Wenn der Dienst das erste Mal seinen Status wechselt unternimmt Nagios max_check_attempts-1 erneute Versuche, bevor es entscheidet, dass ein Problem vorliegt. Diese erneuten Versuche werden durch das Interval, das mit der retry_check_interval-Option angegeben wird, geplant. In diesem Zeitraum befindet sich der Dienst in einem "soften Status". Hat Nagios den Dienst bis zu max_check_attempts-1 Malen erneut überprüft und der Dienst befindet sich immernoch in einem nicht-OK-Status, wird der Status in einen "harten Status" geändert und die nächste Überprüfung wird folglich durch das normale Interval, das durch die check_interval-Option angegeben wird, geplant.
Wird die max_check_attempts-Option allerdings auf einen Wert von 1 gesetzt, wird der Dienst nie durch das mit der retry_check_interval-Option gesetzten Interval erneut überprüft. Stattdessen wird der Status des Dienstes sofort auf einen "harten" Status gesetzt und die nächste Überprüfung des Dienstes durch die normal_check_interval-Option neu geplant.